
BigQueryの構成
BigQueryのプロジェクト、データセット、テーブルがどのような関係性なのかを可視化すると以下のようなイメージになります。
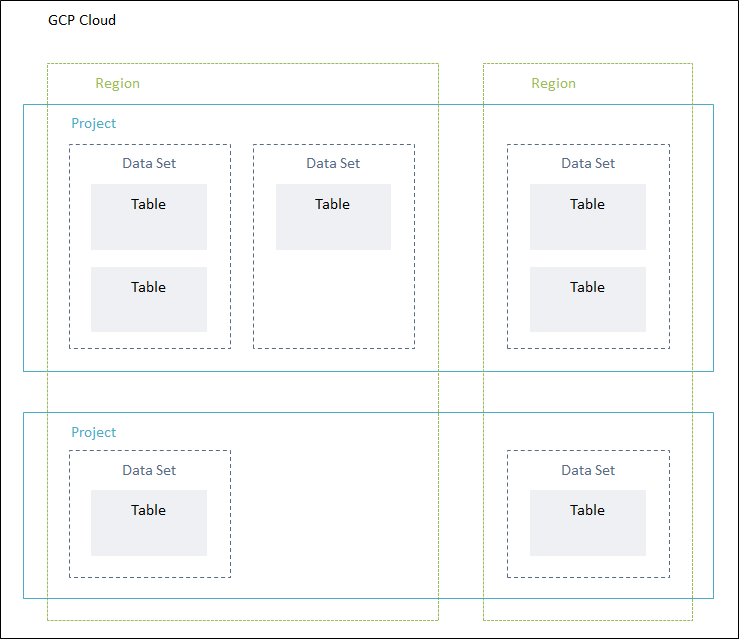
GCPプロジェクト
AWSでいうところのアカウントに相当します。
料金プラン(※)の設定はプロジェクト単位となります。
料金プラン
・オンデマンドプラン ・・・ クエリのデータ量に応じて料金が決まる
・定額プラン ・・・ ○○円で使い放題といった料金プラン
データセット
テーブルやビューを束ねる箱のイメージです。
構成図の通りですが、データセットの配置場所でデータセット配下のテーブルのロケーションも決まります。
注意点
コマンドラインからデータセットを作成する際にロケーションを指定しない場合にUSになりますので、「asia-northeast1」に作成したい場合は必ず指定するようにしましょう。
構成要素
| データセット ID | [GCPプロジェクト]:[データセット名] |
| 作成 | yyyy/MM/dd hh:mm:ss |
| デフォルトのテーブルの有効期限 | 初期値:なし |
| 最終更新 | yyyy/MM/dd hh:mm:ss |
| データのロケーション | 地理的な場所(例.asia-northeast1) |
テーブル
行列形式のデータである点は一般的なRDBのテーブルと同じですが、わかりやすいBigQueryのテーブルの特徴としては以下のものがあります。
特徴
・列指向テーブル
・主キーがない
・インデックスがない
構成要素
| 表 ID | [GCPプロジェクト]:[データセット名].[テーブル名] |
| 表のサイズ | ○○ GBなど |
| 行数 | 登録されているデータ件数 |
| 作成日時 | yyyy/MM/dd hh:mm:ss |
| テーブルの有効期限 | 初期値:なし |
| 最終更新日 | yyyy/MM/dd hh:mm:ss |
| データのロケーション | 地理的な場所 データセットのデータロケーションに依存する |
| テーブルタイプ | 分割 |
| 分割基準 | Day/TimeStampなど |
| フィールドで分割 | 分割対象のフィールド名 |
| パーティション フィルタ | クエリ発行時にパーティションキーに指定した項目をWhere句に含める必要があるかどうか。 必要ない場合は「不要」 |

